Non-sequential Structure-from-Motion for individual objects
If I have made any novel contribution to my field yet, it would probably be this. It's not a huge deal, but I've never seen anyone do it and it solves several niche problems with one elegant change. It's a fun instance of working things out at the frontier of capabilities.
In short: I made a Structure-from-Motion algorithm for reconstructing individual objects. 3D reconstruction is the process of getting a 3D model of some thing from a bunch of images of that thing. Usually the thing in question is actually the entire surrounding environment, and the reconstructed model gives you a sense of the space around you and how you can move through it.
To create this 3D model from a set of images, you need to map out where the camera must have been to take each image. This is referred to as camera extrinsics, or more simply camera mapping. You can see camera mapping in the image below, where an image from each of the red frustums contributes to the reconstruction of a house.

The camera mapping shown above was made with a program called COLMAP, a ubiquitous component of most 3D reconstruction pipelines right now. But for my use case, COLMAP isn't a perfect fit.
COLMAP models the scene, but I am working in space; the "scene" is often complete nothingness, and I only want to reconstruct a single object that I'm looking at. The general use case is superfluous to our needs. Despite being overkill, it still has a couple distinct hangups:
- COLMAP roughly requires all images to be part of one continuous sequence to perform camera mapping. It places images into a constructed sequence in an exhaustive process called image matching. If images cannot be reasonably placed into this sequence, they are dropped from all further reconstruction.
- What if I want to fly past an object multiple times, but contribute all the images I capture to a single reconstruction?
- What if I have multiple observers looking at one target? Can they collaborate on one unified reconstruction?
- COLMAP struggles a lot if the subject you are looking at is itself moving. In space, you are looking at objects that are constantly tumbling. Not good!
- COLMAP takes pretty long. The matching process has something like polynomial time complexity with respect to the amount of images.
This sucks! But remember that this camera mapping paradigm was tailored for the general case of reconstructing scenes, and my use case only requires me to reconstruct one object. Perhaps there's another way we can represent this:
What if we model the "scene" as a hub-and-spoke network centered on our target object, and the edges of that network represent the offsets of the cameras from that target? For each offset, we can find the magnitude from a distance estimation model, and the direction from an attitude estimation model.
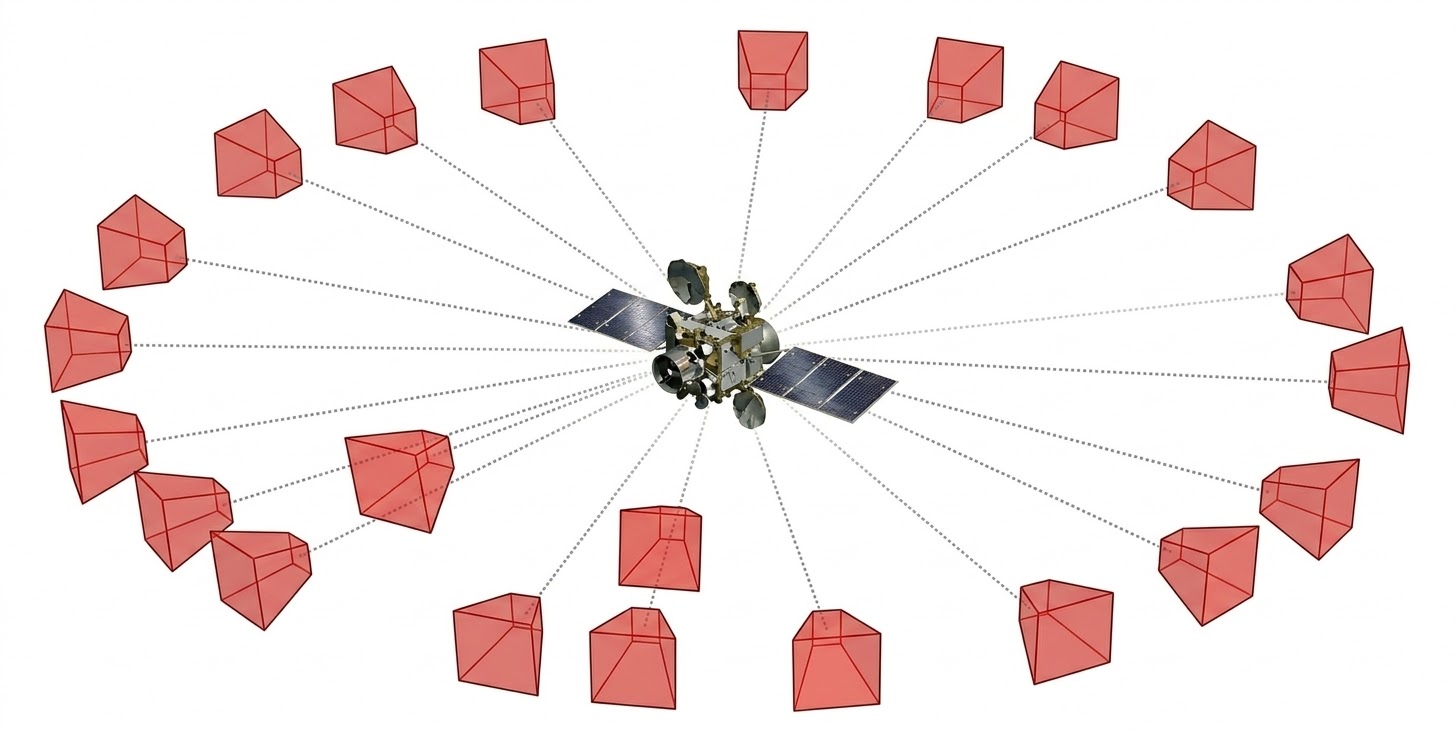
An AI-generated visualization of the hub-and-spoke system. Disregard that the frustums are pointing the wrong way.
How do we make a direction or attitude estimation model? Well, for the purposes of creating this new reconstruction algorithm, I don't really care! If you work in computer vision, you or the people around you are constantly finding better and better ways to estimate direction or attitude. If you know that theoretically you can find your offset based on some given direction and attitude measurements, you don't need to reinvent the wheel to actually get those measurements; you can expect them as inputs. This is the idea of modularity in systems design, and it is great for cutting down on wasted work at a frontier where capabilities are always getting pushed forward.
So, we will expect good distance and attitude estimations per each image. We can construct our hub-and-spoke network by arbitrarily setting the first attitude we encounter as the object's origin attitude, and we draw an edge out from the object at this attitude with a length of our identified distance. This edge represents where the camera is in the 3D scene. Then, for each subsequent image, we can measure the displacement in estimated attitude from that origin attitude and draw edges accordingly.
When we formulate the problem in this way, we elegantly shirk all of our original hangups.
- Because we are not performing image matching to create camera mappings, we can handle images outside of one continuous sequence! This not only enables us to support multiple inspections from one observer contributing to a single reconstruction, but also allows us to support multiple observers simply through treating them as distinct sequences of their own.
- We can model a rotating object because our network only consists of the relative perspective of each camera to the target object. In an instance of the target rotating 40 degrees clockwise from its origin attitude, it would be represented identically to an instance of the camera taking an image 40 degrees through a clockwise orbit of a stationary object.
- This process takes much, much less time than COLMAP.
Now that we have camera mappings via our hub-and-spoke network, how do we actually use the camera locations to make a model? Normally, COLMAP creates a rough point cloud of the scene (referred to as a structural prior) which then gets further refined in later steps of the 3D reconstruction process. Since we are not using COLMAP, we need to make that ourselves.

Here you can see the rough initial model of a bulldozer being made in COLMAP.
Again, since our case is confined to a single object, we can approach the problem more elegantly. For each image, we can create a segmented mask of the object, maybe with some segmentation model like SAM 2. Then, we can project the mask out from each camera in our 3D space. Assuming we know the camera intrinsics per-image (like the camera's focal length) we can project the mask as an extension of each camera frustum in the scene such that the intersections of all projections bound a rough shape of the target object!
Look upon my beautiful animation which explains this better than words ever could.

We have now created camera mappings and a structural prior! This is typically all you need for most fancy 3D reconstruction techniques. To test this I animated three inspection orbits of an object at different perspectives.

Theoretically I could choose a random subset of images from all three orbits combined and get a structural prior from them.
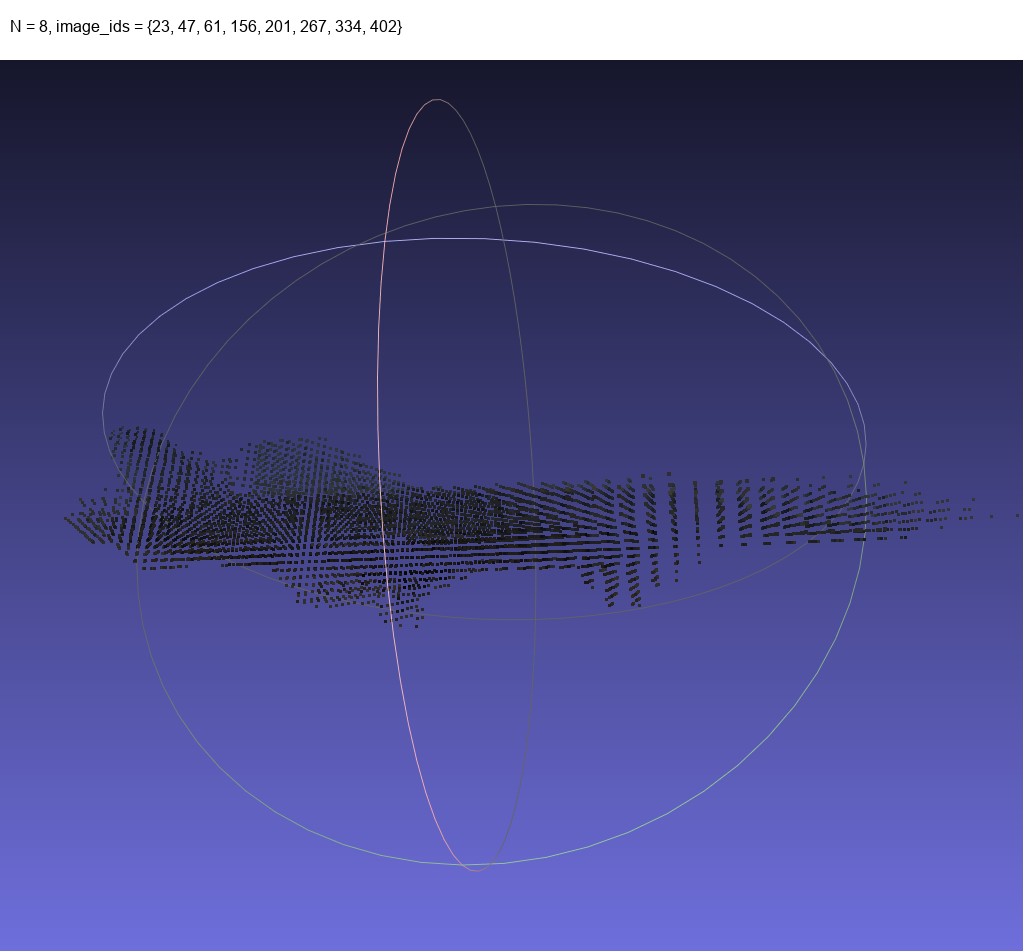
Looking good!
So yeah. Pretty cool. I described this technique to 3D vision hotshot and billionaire philanthropist playboy MrNeRF. He said this might even scale to being a good initialization step for scene-wide structural prior generation if you treat some object within it as an anchor, which I am now fiddling around with.